From Local RAG to Production-Grade: My Next Step in Building AI Systems
TL;DR: I evolved a local Go/Genkit RAG prototype into a cloud-native, multi-model GCP platform with abstraction layers, evaluation and regression safety, grounded responses, and production-aware observability and cost control.
Six months ago, I wrote about building a local RAG chatbot using Genkit, Go, and Ollama.
That project was intentionally simple:
- Local LLM
- Local embeddings
- Local vector store
- Developer UI
- Fully self-contained
It was a great way to understand retrieval-augmented generation deeply — without cloud complexity.
But after that project, one question stayed with me:
What changes when you move from a local RAG experiment to a production-shaped AI system?
Over the past few weeks, I built a second project to answer that question — a cloud-native, multi-model RAG platform designed with production realities in mind. This wasn’t about building a better chatbot. It was about engineering discipline.
What Changes Between “Local” and “Production”?
In my earlier local setup:
- Models ran via Ollama
- Embeddings were local
- Vector storage was filesystem-based
- Debugging happened in Dev UI
- Everything was under my control
In production, things are different.
I now need to think about:
- Model abstraction
- Provider switching
- Regression safety
- Observability
- Cloud networking
- Secrets management
- Cost control
- Deployment repeatability
That shift in mindset changes the architecture significantly.
The Production-Shaped Architecture
The new system utilises the Google Cloud Platform :
- FastAPI backend
- Postgres + pgvector (Cloud SQL)
- Cloud Run deployment
- React frontend (Firebase Hosting)
- LLM provider abstraction layer
- Evaluation harness with regression gating
- Structured logging and tracing
Rather than using a local vector store, embeddings are persisted in Postgres. Instead of relying on a single model, providers are abstracted. Rather than manually inspecting outputs, results are evaluated and scored. For demonstration purposes, the embedding dimension is currently set to 8 to keep the demo lightweight and cost-efficient. In future iterations, I plan to experiment with higher-dimensional embeddings to evaluate retrieval quality trade-offs.
Multi-Model Abstraction
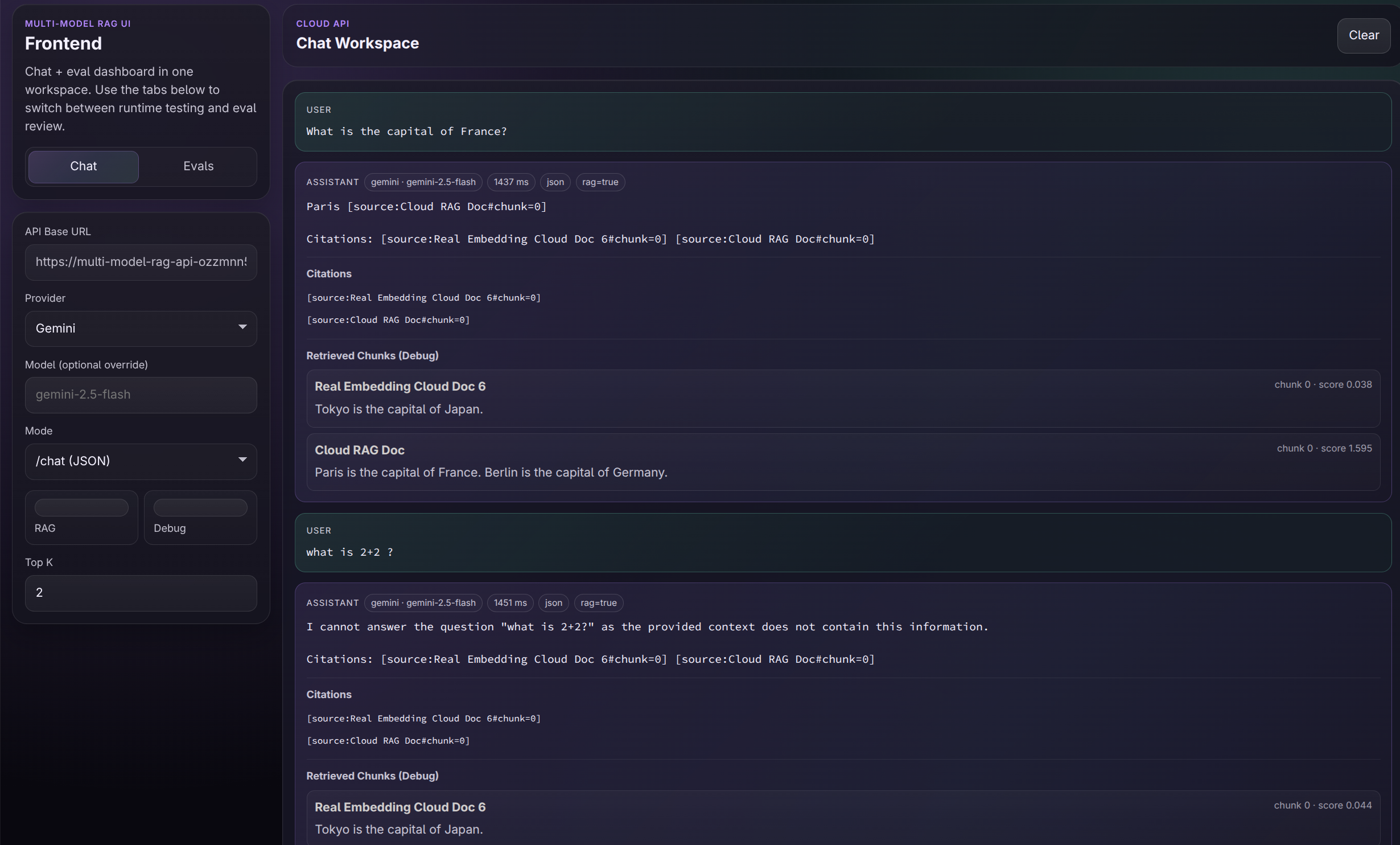
In the local project, the model was fixed. In this version, I introduced a provider abstraction layer so that:
- Generation calls are routed dynamically
- Embeddings are provider-agnostic
- Providers can be swapped without rewriting orchestration logic
Currently:
- Gemini is validated in cloud (generation + embeddings)
- OpenAI adapter is implemented
- Grok provider support implemented (runtime validation depends on API key/quota)
- Additional providers are planned
Designing this separation early makes future experimentation safer.
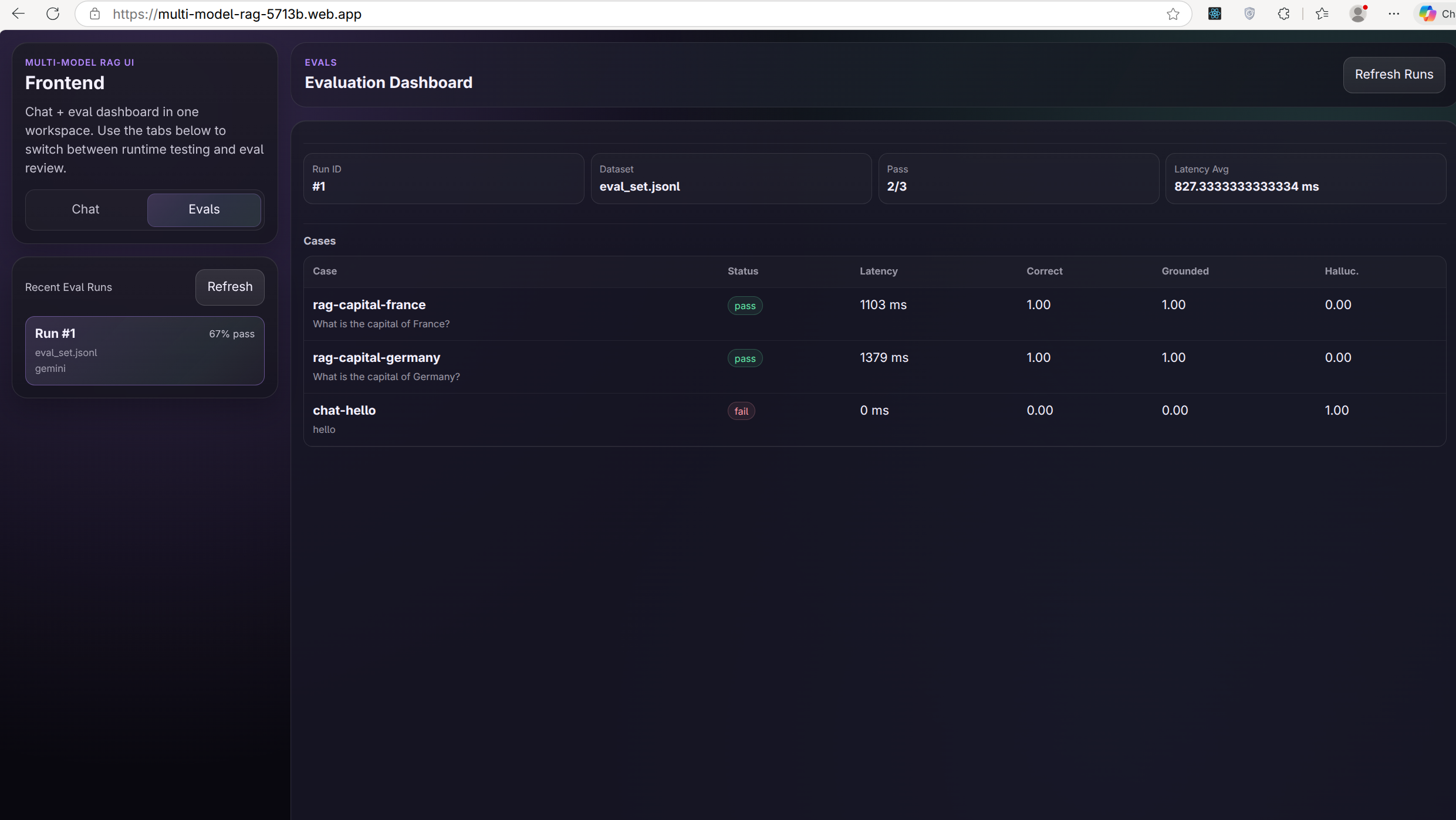
Evaluation & Regression Gating
One thing I realised while working locally: changing prompts or embeddings can subtly degrade output quality. In production, that’s risky.
So this system includes:
- JSONL-based evaluation datasets
- heuristic scoring (correctness, groundedness, hallucination)
- Baseline comparison
- Regression gating
This turns RAG experimentation into something measurable. In this demo, for out-of-scope questions such as “What is 2+2?” against a capitals-only document, the system still retrieves the nearest available chunks, but the model is instructed to answer only from the provided context. As a result, it abstains and responds that the provided context does not contain the required information. This is exactly the kind of grounded behaviour we want from a RAG system, even when retrieval is imperfect.
Cloud Realities
Deploying to Cloud Run + Cloud SQL introduced practical constraints:
- Secret management (via Secret Manager)
- Database connectivity configuration
- Cold start behaviour
- Logging for remote debugging
- Billing-aware infrastructure decisions
For example, since this runs on a personal GCP account, I designed the system to fail predictably when Cloud SQL is paused outside testing windows. The frontend is hosted on Firebase Hosting. For this kind of production-style frontend deployment, Firebase provides a very straightforward and reliable workflow, especially when combined with Cloud Run backends.
Observability
In the local Genkit setup, debugging was visual and immediate.
In the cloud, you need:
- Structured logs
- Request-level tracing
- Retrieval inspection
- Eval dashboards
Without visibility, a RAG pipeline becomes a black box. Incorporating observability early on made troubleshooting significantly easier.
Takeaways from this project
Moving from local RAG → production-shaped RAG reinforced a few lessons:
- Model abstraction is easier to design upfront than retrofit later.
- Evaluation must be a first-class concern.
- Retrieval transparency is essential for debugging.
- Cloud environments expose architectural weaknesses quickly.
- Production constraints influence design decisions more than model quality does.
The biggest shift wasn’t technical — it was mental.
Next Iterations
There are several areas I plan to expand:
-
Adding additional providers for broader benchmarking
-
Introducing rate limiting and gateway restrictions for public demo protection
-
Implementing billing safeguards to prevent uncontrolled usage
-
CI is in place; deployments are currently manual via repeatable scripts, with full CD planned next.
#AIEngineering #RAG #LLM #CloudArchitecture #SoftwareEngineering #GCP